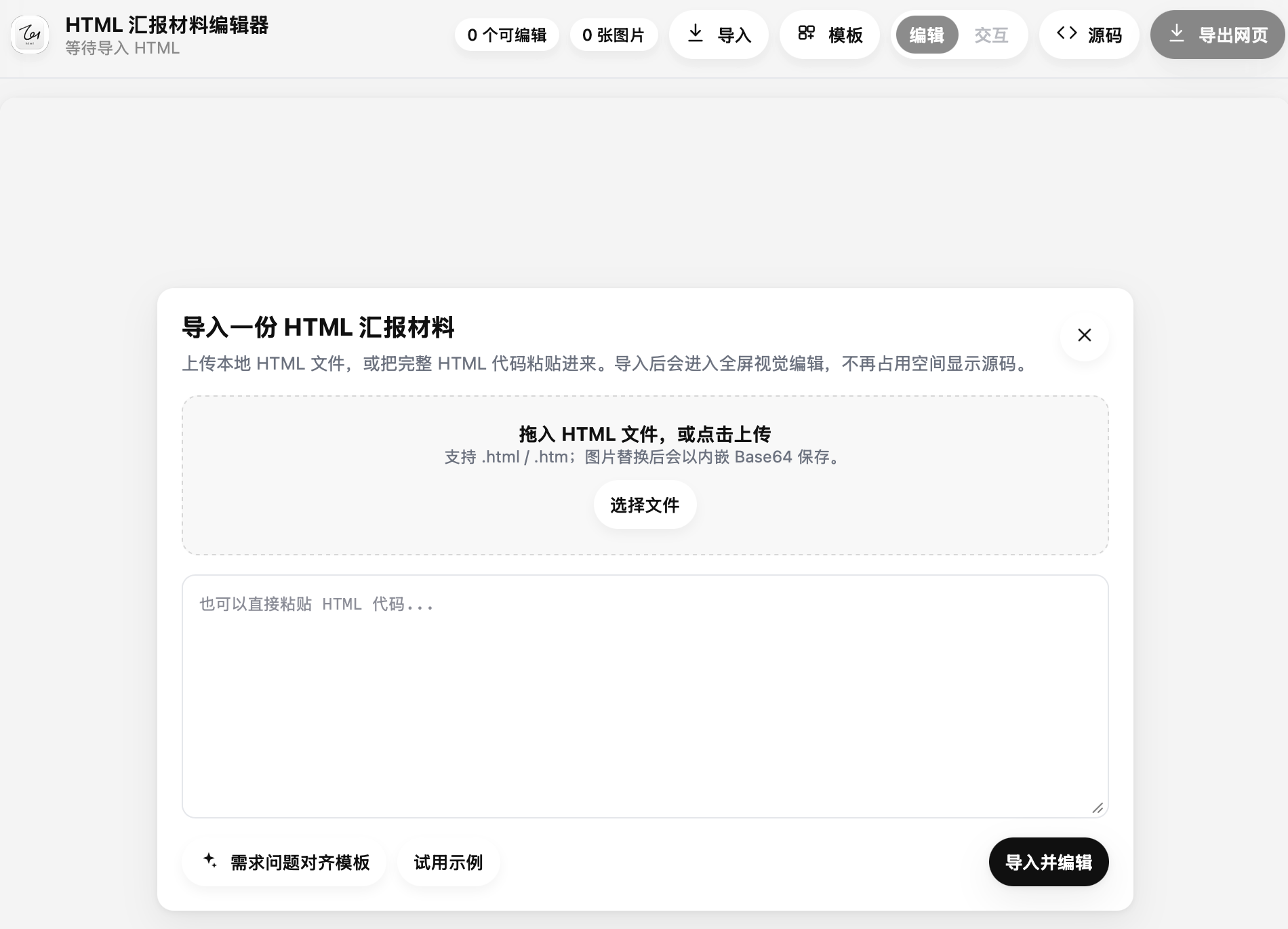
.html HTML Editor报告生成后还能改
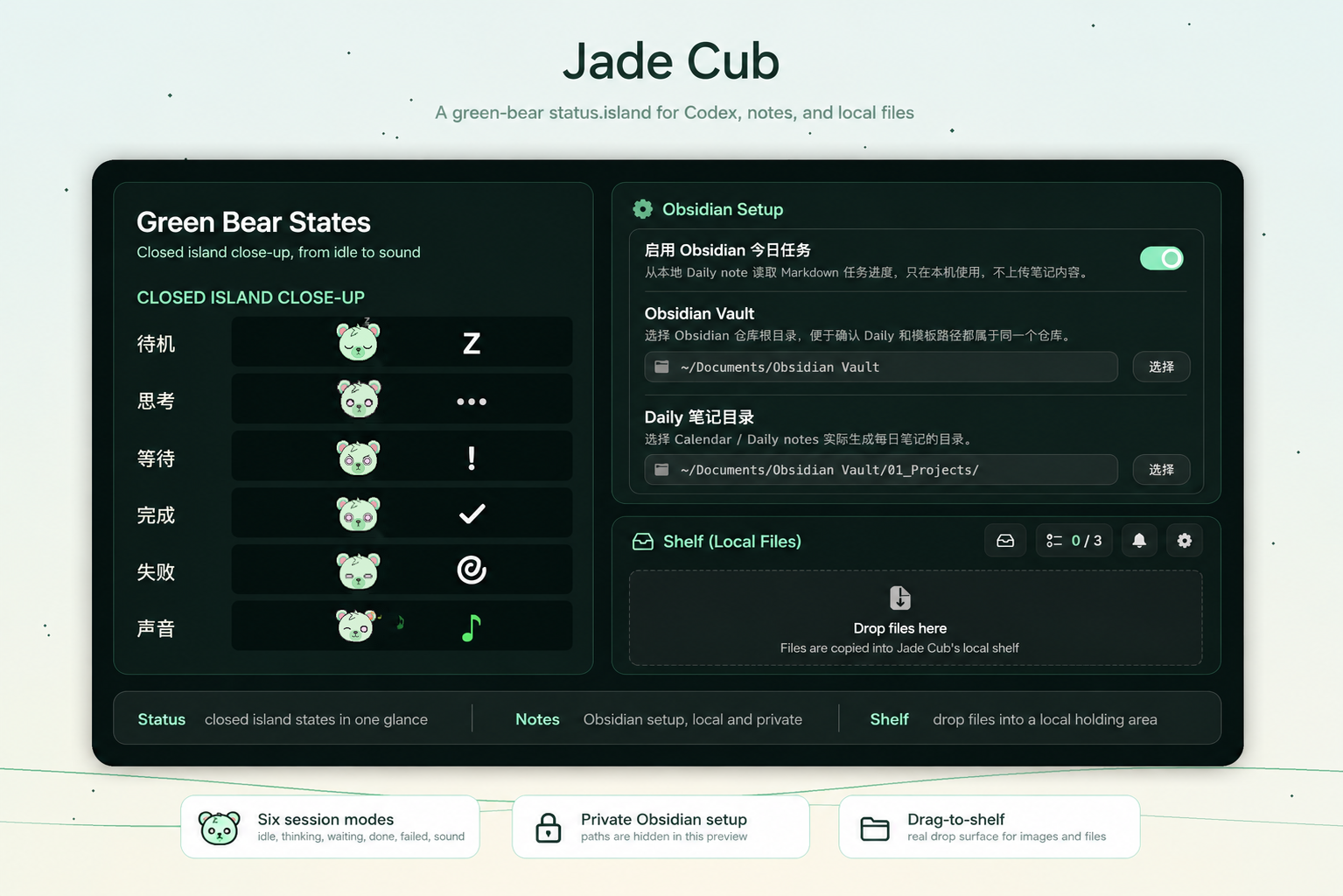
jade Jade Cub会话、任务、审批同屏
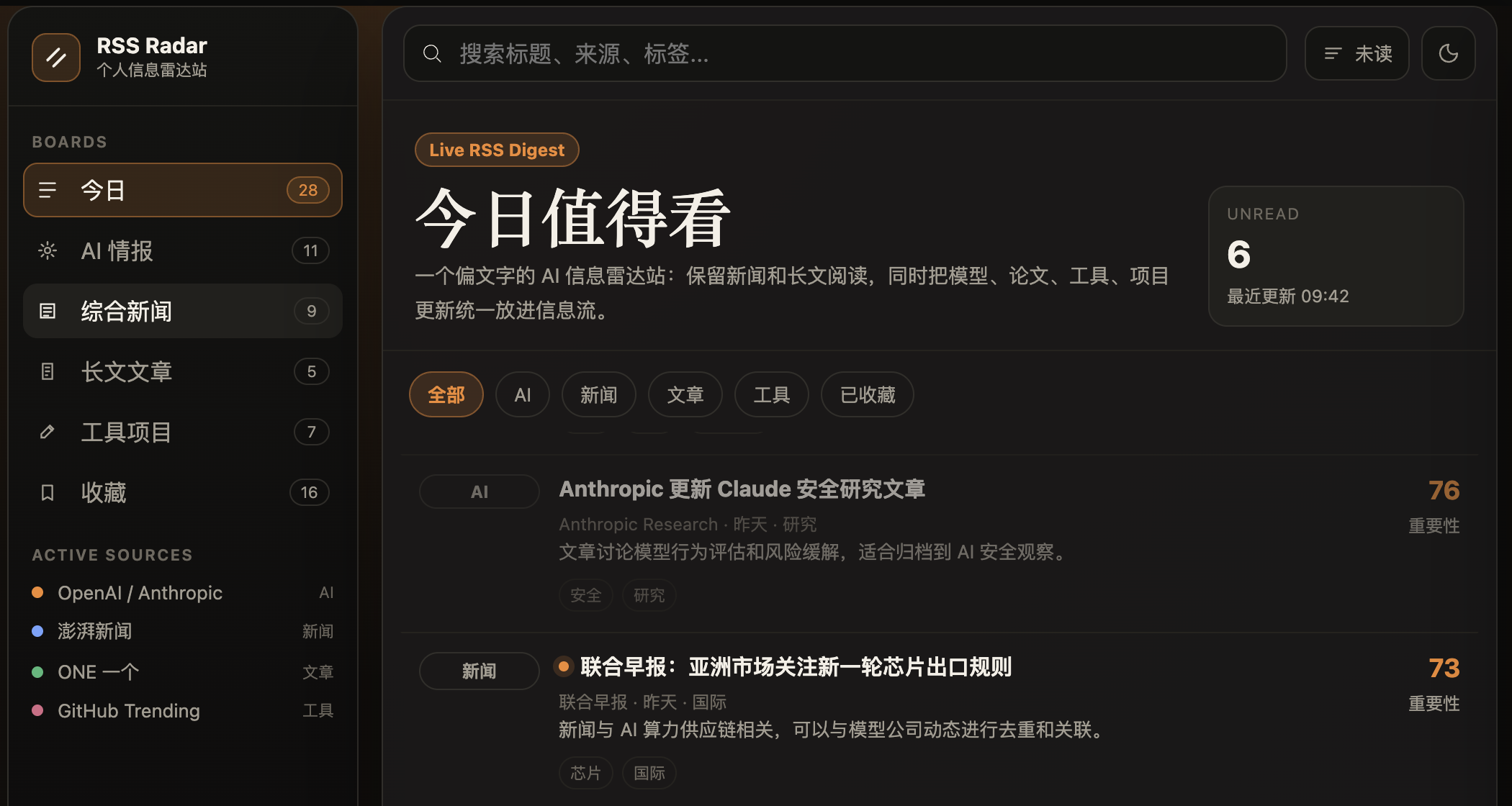
rss.xml RSS Radar来源变成待处理列表
三件事其实是一条线:材料进入工具,判断留在界面。
三个项目。
每个项目对应一个具体断点,保留真实截图和设计取舍。
这些项目从哪里来。
很多工作场景并不缺信息。文件、网页、表格、PPT 和聊天记录已经在那里,缺的是能继续推进的结构。
我会从材料进入界面的那一刻看起,再决定编辑、整理和带走的路径。
这些界面通常这样处理。
材料、状态和出口,是这些小工具反复处理的三件事。
从具体材料入手
截图、文件、字段和导出结果,会告诉界面应该长成什么样。
把状态说清楚
人需要知道当前在哪里、什么完成了、下一步该做什么。
保留修改的入口
输出之后还能编辑、导出和归档,工具才真正留下来。
碎片怎样变成可用材料。
语音、微信、网页和临时想法先进入固定入口,再转写、摘要、路由,最后回到 Obsidian。
这套流程把输入、摘要、待办和归档分开处理,减少临时记忆的负担。
- 输入语音、微信、网页保留为原始记录。
- 整理转写、摘要、待办和标题成形。
- 流转n8n 把消息写进固定目录。
- 沉淀Codex 与 Obsidian 继续整理成方法文档。
从具体材料里看工作流。
截图集中展示四个切面:输入、整理、流转和沉淀。
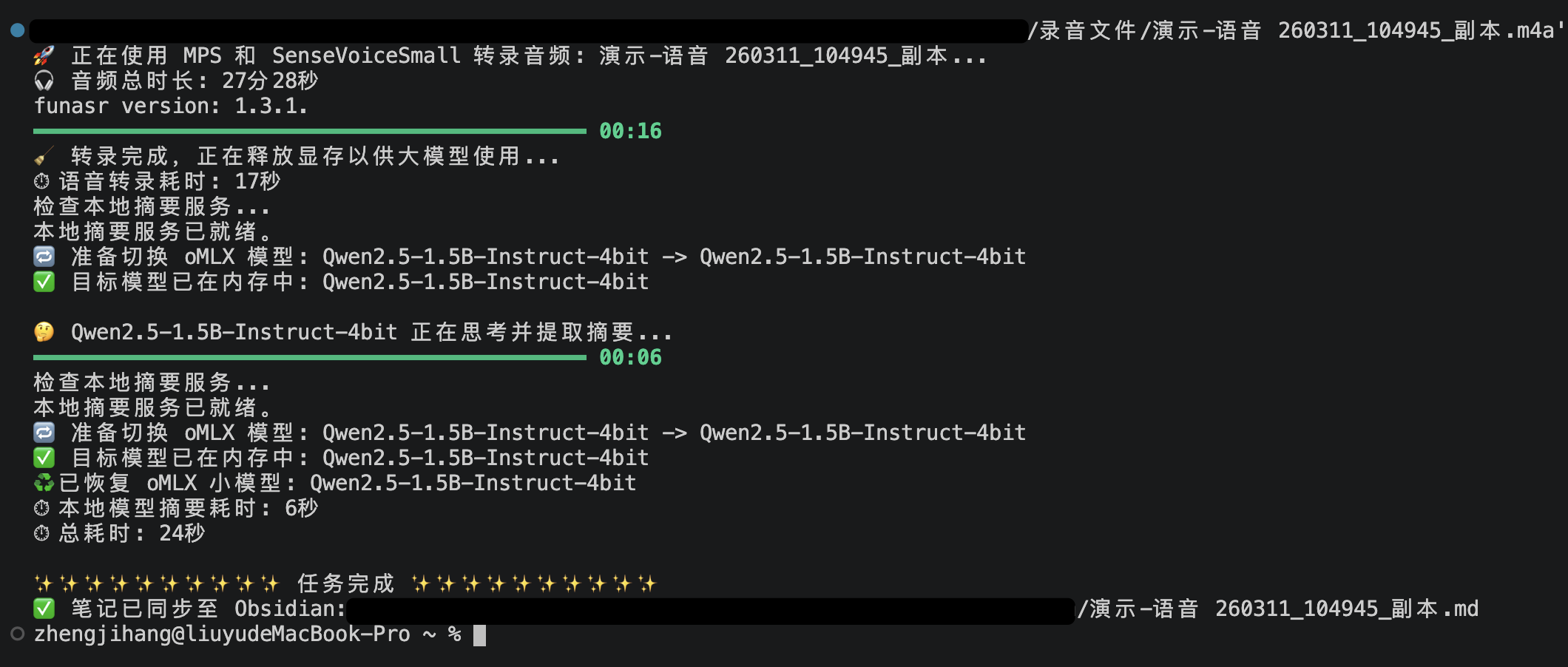
 Recording
Recording 收住语音和临时想法
降低记录成本,让语音、临时备忘和网页内容进入同一个入口。

 omlx
omlx 让模型做第一轮结构化
模型先给出摘要、议题和待办。它只负责让混乱内容变得可读。
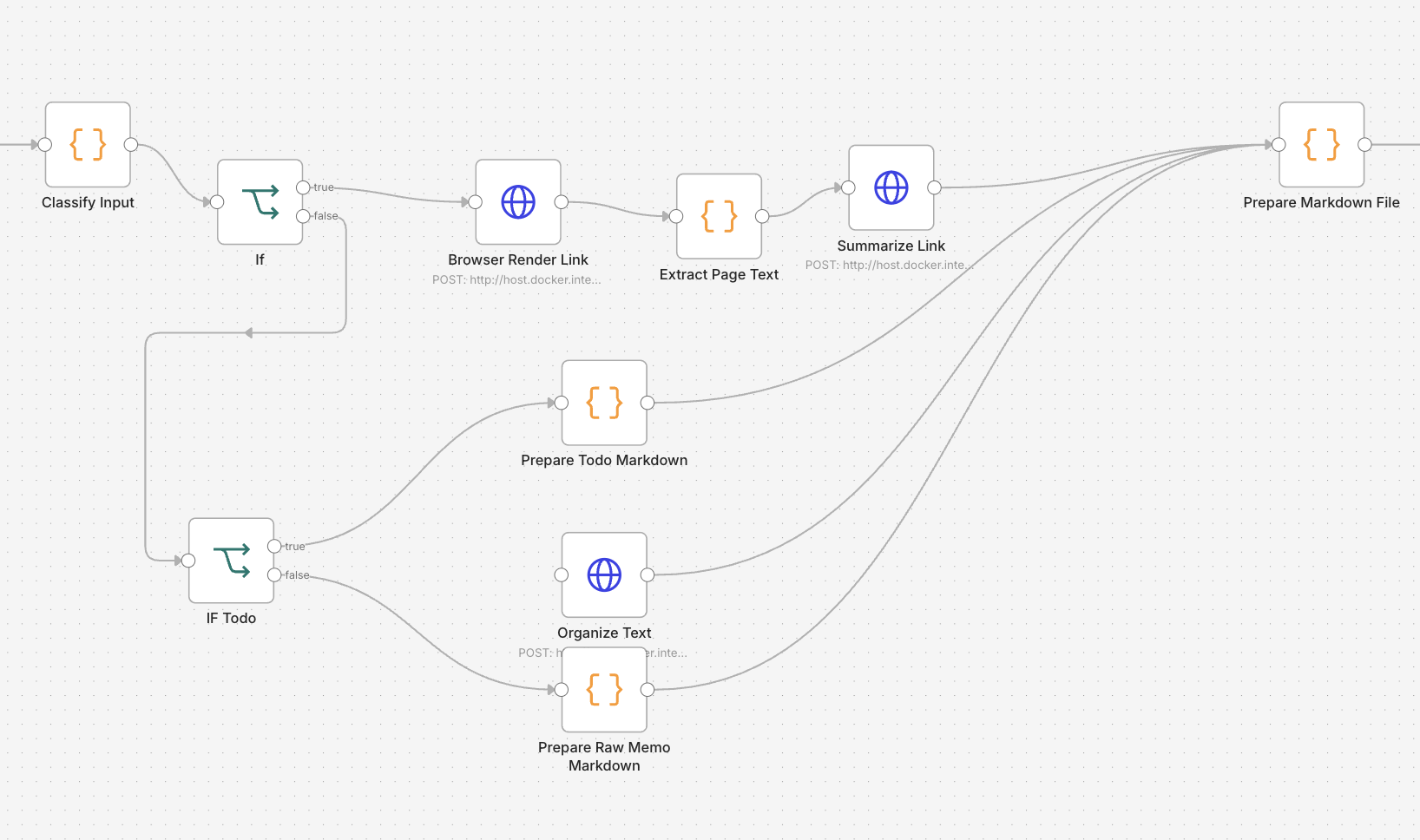

 n8n
n8n 让消息自动到达固定位置
n8n 判断内容类型,生成对应 Markdown,把备忘和待办写到固定目录。
 Obsidian
Obsidian 回到个人知识库
材料需要能被搜索、引用,并逐步长成长期方法。
正在形成的方向。
这些主题暂时作为索引,等有完整截图和取舍后再进入作品区。
- 医疗 BI高密度指标、科室对比和运营驾驶舱。
- 运营报表预算、收入、KPI 和经营分析材料的网页化表达。
- 网页 PPT适合演示的 HTML deck,保留节奏和现场讲述感。
- 文章视觉卡片把观点、流程和结构做成可传播的长图。
我是 liuyuplus。
我做本地优先的小工具、报表界面和 AI 工作流。重点是让复杂材料能被看见、修改和继续使用。
- 本地优先重要材料尽量留在用户身边。
- 状态可见进度、风险和下一步要被看见。
- 能继续输出之后,还要能编辑、整理和导出。